データ分析実践
初級問題チェック
問題 5 /40
pandasのapply、map、applymapメソッドに関して、誤った結果はどれか。
df
▶︎
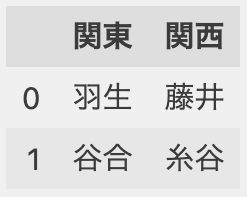
選択 1
df = df.apply(lambda x: x + '先生')
df
▶︎

選択 2
df['関東'] = df['関東'].map(lambda x: x + '先生')
df
▶︎

選択 3
df['関西'] = df.loc[:, '関西'].applymap(lambda x: x + '先生')
df
▶︎

選択 4
df['関西'] = df['関西'].map({'藤井': '藤井先生', '糸谷': '糸谷先生'})
df
▶︎
解説
選択肢3が正解です。
apply、map、applymapメソッドは、対応できる処理に違いがあります。
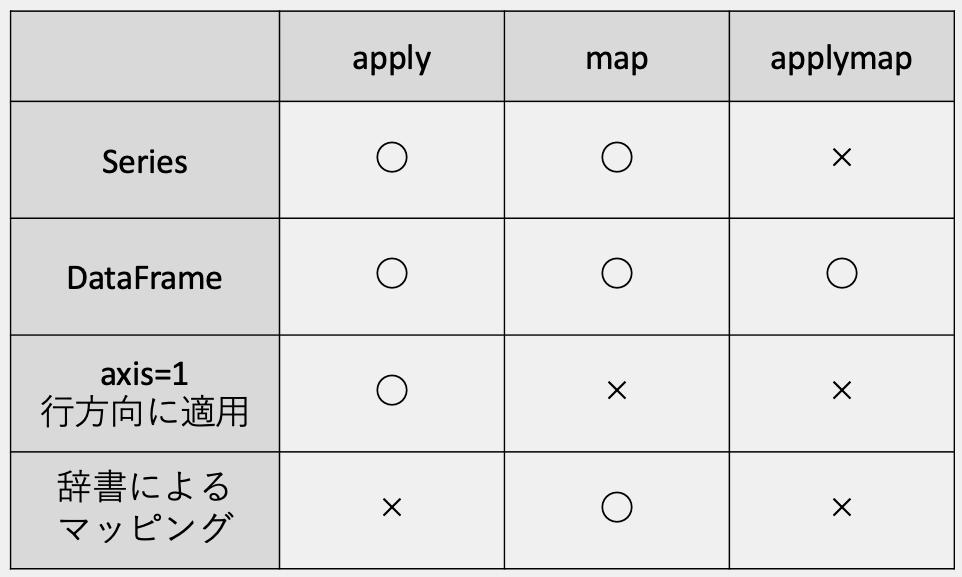 実用的なのは、Series、DataFrame、行方向に対応したapplyメソッドです。辞書によるマッピングを利用するときはmapメソッドを使います。applymapメソッドは廃止予定となっています。
問題文のDataFrameです。
df = pd.DataFrame(
{'関東': ['羽生', '谷合'],
'関西': ['藤井', '糸谷']})
▶︎
【選択肢1】
df = df.apply(lambda x: x + '先生')
df
▶︎
正しい結果です。
applyメソッドはSeriesとDataFrameの両方に対応しています。ここではDataFrameの各値に「先生」を付加しています。
lambda式は無名関数と呼ばれており、defで関数を定義するほどではない小さな処理をする際に利用します。構文は「lambda 引数 : 式」で、式で使用した変数を、lambdaの後に続く引数に渡します。コロンの前の「lambda 引数」が「式の返り値」と考えると分かりやすいです。
このlambda式をapplyメソッドなどに渡すことにより、DataFrameやSeriesの各値に処理を適用することができます。
【選択肢2】
df['関東'] = df['関東'].map(lambda x: x + '先生')
df
▶︎
正しい結果です。
mapメソッドはSeriesの各値に処理を適用できます。
選択肢2のように末尾に文字列を追加するだけなら、次の記述でも可能です。
df['関東'] = df['関東'] + '先生'
lambda式の用途は、Pythonやpandasの既存の関数で処理できない場合に使います。
例えば次のように、「値」の数値を小数点第2位にする場合に利用します。
df
▶︎
実用的なのは、Series、DataFrame、行方向に対応したapplyメソッドです。辞書によるマッピングを利用するときはmapメソッドを使います。applymapメソッドは廃止予定となっています。
問題文のDataFrameです。
df = pd.DataFrame(
{'関東': ['羽生', '谷合'],
'関西': ['藤井', '糸谷']})
▶︎
【選択肢1】
df = df.apply(lambda x: x + '先生')
df
▶︎
正しい結果です。
applyメソッドはSeriesとDataFrameの両方に対応しています。ここではDataFrameの各値に「先生」を付加しています。
lambda式は無名関数と呼ばれており、defで関数を定義するほどではない小さな処理をする際に利用します。構文は「lambda 引数 : 式」で、式で使用した変数を、lambdaの後に続く引数に渡します。コロンの前の「lambda 引数」が「式の返り値」と考えると分かりやすいです。
このlambda式をapplyメソッドなどに渡すことにより、DataFrameやSeriesの各値に処理を適用することができます。
【選択肢2】
df['関東'] = df['関東'].map(lambda x: x + '先生')
df
▶︎
正しい結果です。
mapメソッドはSeriesの各値に処理を適用できます。
選択肢2のように末尾に文字列を追加するだけなら、次の記述でも可能です。
df['関東'] = df['関東'] + '先生'
lambda式の用途は、Pythonやpandasの既存の関数で処理できない場合に使います。
例えば次のように、「値」の数値を小数点第2位にする場合に利用します。
df
▶︎
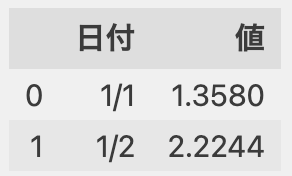 df['値'] = df['値'].apply(lambda x: '%.2f'%x)
df
▶︎
df['値'] = df['値'].apply(lambda x: '%.2f'%x)
df
▶︎
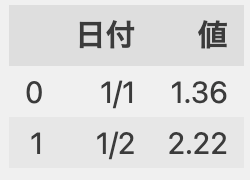 【選択肢3】
df['関西'] = df.loc[:, '関西'].applymap(lambda x: x + '先生')
df
▶︎
誤った結果です。
df.loc[:, '関西']は、df['関西']と同じでSeriesです。applymapメソッドはSeriesに対しては適用できないため、AttributeErrorになります。
「df.loc[:, ['関西']]」や「df.loc[:, ['関東', '関西']]」のように、対象がDataFrameであれば適用できます。
【選択肢4】
df['関西'] = df['関西'].map({'藤井': '藤井先生', '糸谷': '糸谷先生'})
df
▶︎
正しい結果です。
mapメソッドは辞書によるマッピングができます。引数で指定した辞書のキーと一致するフィールドを、指定した値に変換することができます。
(公式書籍 p.34)
【選択肢3】
df['関西'] = df.loc[:, '関西'].applymap(lambda x: x + '先生')
df
▶︎
誤った結果です。
df.loc[:, '関西']は、df['関西']と同じでSeriesです。applymapメソッドはSeriesに対しては適用できないため、AttributeErrorになります。
「df.loc[:, ['関西']]」や「df.loc[:, ['関東', '関西']]」のように、対象がDataFrameであれば適用できます。
【選択肢4】
df['関西'] = df['関西'].map({'藤井': '藤井先生', '糸谷': '糸谷先生'})
df
▶︎
正しい結果です。
mapメソッドは辞書によるマッピングができます。引数で指定した辞書のキーと一致するフィールドを、指定した値に変換することができます。
(公式書籍 p.34)
【選択肢1】
df = df.apply(lambda x: x + '先生')
df
▶︎
正しい結果です。
applyメソッドはSeriesとDataFrameの両方に対応しています。ここではDataFrameの各値に「先生」を付加しています。
lambda式は無名関数と呼ばれており、defで関数を定義するほどではない小さな処理をする際に利用します。構文は「lambda 引数 : 式」で、式で使用した変数を、lambdaの後に続く引数に渡します。コロンの前の「lambda 引数」が「式の返り値」と考えると分かりやすいです。
このlambda式をapplyメソッドなどに渡すことにより、DataFrameやSeriesの各値に処理を適用することができます。
【選択肢2】
df['関東'] = df['関東'].map(lambda x: x + '先生')
df
▶︎
正しい結果です。
mapメソッドはSeriesの各値に処理を適用できます。
選択肢2のように末尾に文字列を追加するだけなら、次の記述でも可能です。
df['関東'] = df['関東'] + '先生'
lambda式の用途は、Pythonやpandasの既存の関数で処理できない場合に使います。
例えば次のように、「値」の数値を小数点第2位にする場合に利用します。
df
▶︎
df['値'] = df['値'].apply(lambda x: '%.2f'%x)
df
▶︎
【選択肢3】
df['関西'] = df.loc[:, '関西'].applymap(lambda x: x + '先生')
df
▶︎
誤った結果です。
df.loc[:, '関西']は、df['関西']と同じでSeriesです。applymapメソッドはSeriesに対しては適用できないため、AttributeErrorになります。
「df.loc[:, ['関西']]」や「df.loc[:, ['関東', '関西']]」のように、対象がDataFrameであれば適用できます。
【選択肢4】
df['関西'] = df['関西'].map({'藤井': '藤井先生', '糸谷': '糸谷先生'})
df
▶︎
正しい結果です。
mapメソッドは辞書によるマッピングができます。引数で指定した辞書のキーと一致するフィールドを、指定した値に変換することができます。
(公式書籍 p.34)