データ分析実践
中級問題チェック
問題 12 /40
pandasのpivot関数でdf1をdf2に変形した後、melt関数でdf2からdf1に戻す場合、melt関数の正しい記述はどれか。
df1
▶︎
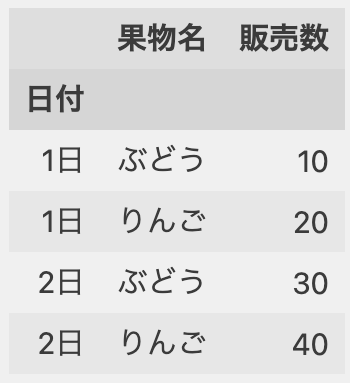 *「日付」はインデックスのタイトル。カラムのタイトルは無し。「果物名」と「販売数」は列の名前。
df2
▶︎
*「日付」はインデックスのタイトル。カラムのタイトルは無し。「果物名」と「販売数」は列の名前。
df2
▶︎
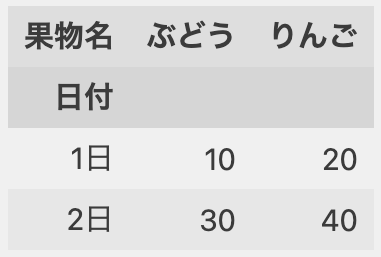 *「日付」はインデックスのタイトル。「果物名」はカラムのタイトル。「ぶどう」と「りんご」は列の名前。
*「日付」はインデックスのタイトル。「果物名」はカラムのタイトル。「ぶどう」と「りんご」は列の名前。
*「日付」はインデックスのタイトル。カラムのタイトルは無し。「果物名」と「販売数」は列の名前。
df2
▶︎
*「日付」はインデックスのタイトル。「果物名」はカラムのタイトル。「ぶどう」と「りんご」は列の名前。選択 1
pd.melt(
df2,
ignore_index=False,
value_vars=['ぶどう','りんご'],
value_name='販売数'
).sort_index()
選択 2
pd.melt(
df2,
value_vars=['ぶどう','りんご'],
value_name='販売数'
).sort_index()
選択 3
pd.melt(
df2,
id_vars='日付',
value_vars=['ぶどう','りんご'],
value_name='販売数'
).sort_index()
選択 4
pd.melt(
df2,
ignore_index=False,
value_vars='果物名',
value_name='販売数'
).sort_index()
解説
選択肢1が正解です。
pivot関数は縦持ちデータを横持ちに変形し、melt関数は横持ちデータを縦持ちに変形します。
df1 = pd.DataFrame(
{'果物名':['ぶどう','りんご','ぶどう','りんご'],
'販売数':[10,20,30,40]},
index=['1日','1日','2日','2日'])
df1.index.name='日付'
df1
▶︎
この縦持ちデータをpivot関数で横持ちに変形します。
df2 = pd.pivot(
df1,
columns='果物名',
values='販売数')
df2
▶︎
このdf2を、melt関数でdf1に戻す記述を考えます。
【選択肢1】
pd.melt(
df2,
ignore_index=False,
value_vars=['ぶどう','りんご'],
value_name='販売数'
).sort_index()
▶︎
正しい結果です。
melt関数の引数は、次の指定になります。
■ id_vars
IDとして使う列を指定。
インデックスにする列名を指定しますが、df2は「日付」のインデックスをIDとして使うため、id_varsは指定しません。
インデックスをIDとして使う場合、「インデックスを無視しない」という意味で「ignore_index=False」をつけます。
■ value_vars
ピボットを解除する列を指定。
一つの列にまとめる列名を指定します。
df2の場合は「ぶどう」と「りんご」を一つの列にまとめて縦持ちにするため、「value_vars=['ぶどう', 'りんご']」とします。
value_varsを指定しなかった場合は、id_varsで指定した列以外のすべての列が解除されます。
■ var_name
value_varsで縦持ちにした列の列名を指定。
df2の「ぶどう」と「りんご」には「果物名」というカラムのタイトルがついているため、var_nameを指定しなくても「果物名」の列名がつきます。「var_name='果物名'」をつけても同じ結果になります。
■ value_name
値の列につける列名を指定。
ここでは値の列に「販売数」という列名をつけています。
【選択肢2】
pd.melt(
df2,
value_vars=['ぶどう','りんご'],
value_name='販売数'
).sort_index()
▶︎
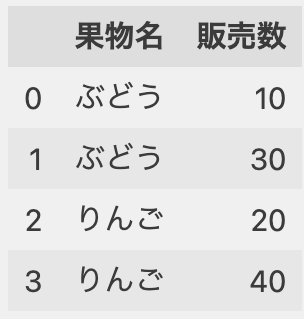 誤った結果です。
選択肢1の引数「ignore_index=False」がないため、インデックスが無視されて消えています。
【選択肢3】
pd.melt(
df2,
id_vars='日付',
value_vars=['ぶどう','りんご'],
value_name='販売数'
).sort_index()
▶︎
KeyError: "The following id_vars or value_vars are not present in the DataFrame: ['日付']"
誤った結果です。
id_varsはインデックスではなく列名を指定します。選択肢3のようにインデックスを指定するとKeyErrorになります。
df2の「日付」が、次のようにインデックスではなく列であれば、id_varsで指定できます。
df2 = pd.pivot(
df1.reset_index(),
index='日付',
columns='果物名',
values='販売数',
).reset_index()
df2
▶︎
誤った結果です。
選択肢1の引数「ignore_index=False」がないため、インデックスが無視されて消えています。
【選択肢3】
pd.melt(
df2,
id_vars='日付',
value_vars=['ぶどう','りんご'],
value_name='販売数'
).sort_index()
▶︎
KeyError: "The following id_vars or value_vars are not present in the DataFrame: ['日付']"
誤った結果です。
id_varsはインデックスではなく列名を指定します。選択肢3のようにインデックスを指定するとKeyErrorになります。
df2の「日付」が、次のようにインデックスではなく列であれば、id_varsで指定できます。
df2 = pd.pivot(
df1.reset_index(),
index='日付',
columns='果物名',
values='販売数',
).reset_index()
df2
▶︎
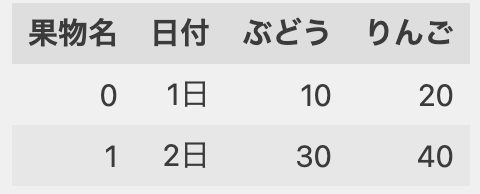 *「果物名」はカラムのタイトル。
pd.melt(
df2,
id_vars='日付',
value_vars=['ぶどう','りんご'],
value_name='販売数'
).set_index('日付').sort_index()
▶︎
value_varsを指定しなかった場合は、すべての列が解除されます。「ぶどう」と「りんご」は、id_varsで指定した「日付」以外の全ての列になるため、「value_vars=['ぶどう', 'りんご']」の引数がなくても同じ結果になります。
各引数のイメージは以下です。
*「果物名」はカラムのタイトル。
pd.melt(
df2,
id_vars='日付',
value_vars=['ぶどう','りんご'],
value_name='販売数'
).set_index('日付').sort_index()
▶︎
value_varsを指定しなかった場合は、すべての列が解除されます。「ぶどう」と「りんご」は、id_varsで指定した「日付」以外の全ての列になるため、「value_vars=['ぶどう', 'りんご']」の引数がなくても同じ結果になります。
各引数のイメージは以下です。
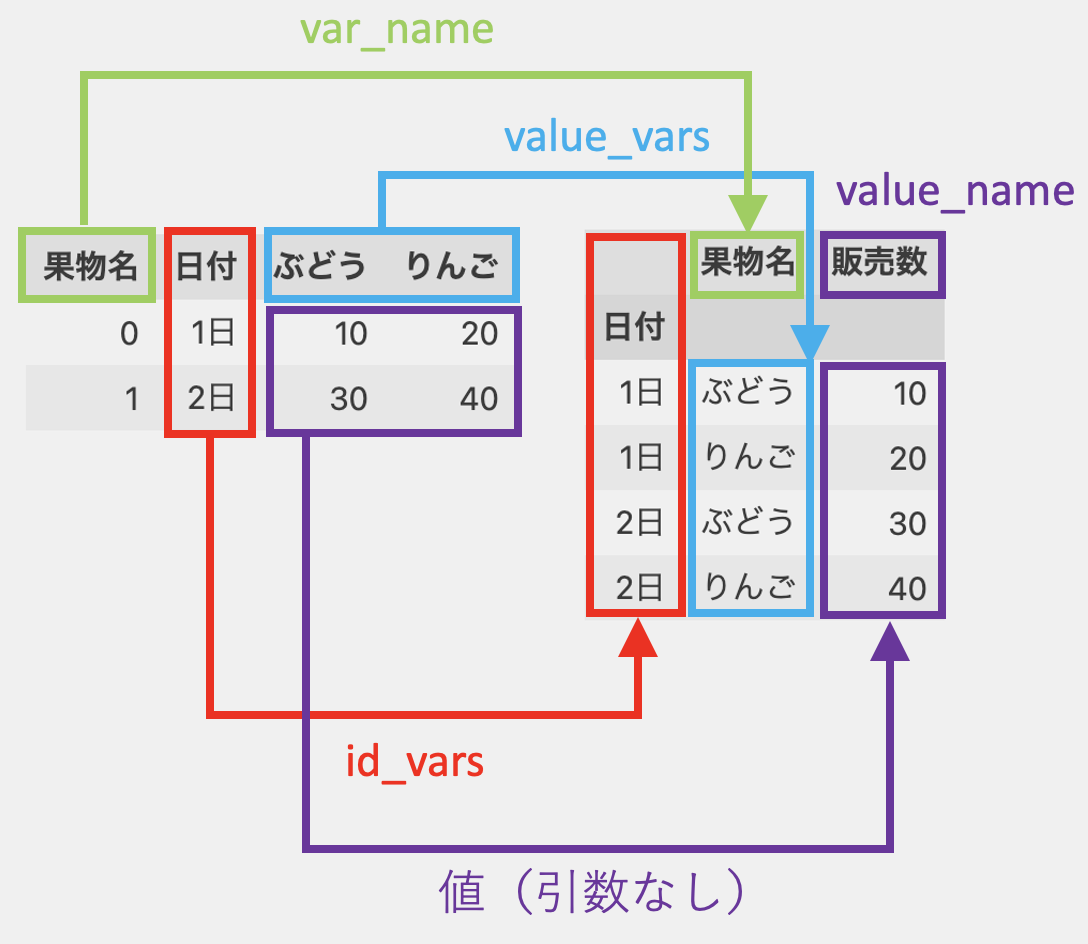 melt関数の引数は紛らわしいので、この図をイメージすると覚えやすいかもしれません。
【選択肢4】
pd.melt(
df2,
ignore_index=False,
value_vars='果物名',
value_name='販売数'
).sort_index()
▶︎
KeyError: "The following id_vars or value_vars are not present in the DataFrame: ['果物名']"
誤った結果です。
value_varsは「value_vars=['ぶどう', 'りんご']」のように、縦持ちにする列名を指定します。「果物名」は列名ではなくカラムのタイトルのため、KeyErrorになります。
(公式書籍 p.93-94)
melt関数の引数は紛らわしいので、この図をイメージすると覚えやすいかもしれません。
【選択肢4】
pd.melt(
df2,
ignore_index=False,
value_vars='果物名',
value_name='販売数'
).sort_index()
▶︎
KeyError: "The following id_vars or value_vars are not present in the DataFrame: ['果物名']"
誤った結果です。
value_varsは「value_vars=['ぶどう', 'りんご']」のように、縦持ちにする列名を指定します。「果物名」は列名ではなくカラムのタイトルのため、KeyErrorになります。
(公式書籍 p.93-94)
この縦持ちデータをpivot関数で横持ちに変形します。
df2 = pd.pivot(
df1,
columns='果物名',
values='販売数')
df2
▶︎
このdf2を、melt関数でdf1に戻す記述を考えます。
【選択肢1】
pd.melt(
df2,
ignore_index=False,
value_vars=['ぶどう','りんご'],
value_name='販売数'
).sort_index()
▶︎
正しい結果です。
melt関数の引数は、次の指定になります。
■ id_vars
IDとして使う列を指定。
インデックスにする列名を指定しますが、df2は「日付」のインデックスをIDとして使うため、id_varsは指定しません。
インデックスをIDとして使う場合、「インデックスを無視しない」という意味で「ignore_index=False」をつけます。
■ value_vars
ピボットを解除する列を指定。
一つの列にまとめる列名を指定します。
df2の場合は「ぶどう」と「りんご」を一つの列にまとめて縦持ちにするため、「value_vars=['ぶどう', 'りんご']」とします。
value_varsを指定しなかった場合は、id_varsで指定した列以外のすべての列が解除されます。
■ var_name
value_varsで縦持ちにした列の列名を指定。
df2の「ぶどう」と「りんご」には「果物名」というカラムのタイトルがついているため、var_nameを指定しなくても「果物名」の列名がつきます。「var_name='果物名'」をつけても同じ結果になります。
■ value_name
値の列につける列名を指定。
ここでは値の列に「販売数」という列名をつけています。
【選択肢2】
pd.melt(
df2,
value_vars=['ぶどう','りんご'],
value_name='販売数'
).sort_index()
▶︎
誤った結果です。
選択肢1の引数「ignore_index=False」がないため、インデックスが無視されて消えています。
【選択肢3】
pd.melt(
df2,
id_vars='日付',
value_vars=['ぶどう','りんご'],
value_name='販売数'
).sort_index()
▶︎
KeyError: "The following id_vars or value_vars are not present in the DataFrame: ['日付']"
誤った結果です。
id_varsはインデックスではなく列名を指定します。選択肢3のようにインデックスを指定するとKeyErrorになります。
df2の「日付」が、次のようにインデックスではなく列であれば、id_varsで指定できます。
df2 = pd.pivot(
df1.reset_index(),
index='日付',
columns='果物名',
values='販売数',
).reset_index()
df2
▶︎
*「果物名」はカラムのタイトル。
pd.melt(
df2,
id_vars='日付',
value_vars=['ぶどう','りんご'],
value_name='販売数'
).set_index('日付').sort_index()
▶︎
value_varsを指定しなかった場合は、すべての列が解除されます。「ぶどう」と「りんご」は、id_varsで指定した「日付」以外の全ての列になるため、「value_vars=['ぶどう', 'りんご']」の引数がなくても同じ結果になります。
各引数のイメージは以下です。