データ分析実践
上級問題チェック
問題 4 /40
pandasのExcelファイルの読み書きに関して、誤った説明はどれか。
選択 1
上下に結合されたセルをread_excel関数で読み込むと、一番上のフィールドだけ値が反映し、下のフィールドはNaNになる。
選択 2
日付を含むExcelファイルをread_excel関数で読み込む場合、日付が数値になることがある。
選択 3
MultiIndexのDataFrameをto_excelメソッドで書き出すとエラーになる。
選択 4
二つのDataFrameを、一つのExcelファイルで二つのシートに分けて書き出す場合は、ExcelWriter関数を使う。
解説
選択肢3が正解です。
【選択肢1】
上下に結合されたセルをread_excel関数で読み込むと、一番上のフィールドだけ値が反映し、下のフィールドはNaNになる。
正しい説明です。
次のように、店舗名のセルが上下に結合されたExcelファイルを読み込むと、上のフィールドだけ値が反映し、残りはNaNになります。
sample.xlsx
▶︎
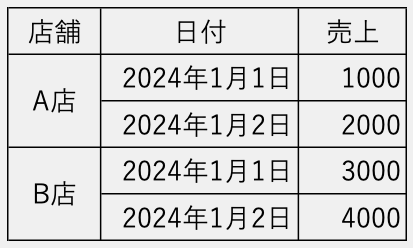 df = pd.read_excel('sample.xlsx')
df
▶︎
df = pd.read_excel('sample.xlsx')
df
▶︎
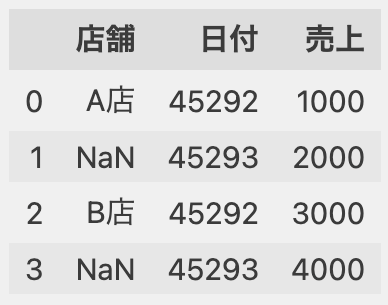 このNaNを上のセルと同じ値で補完する場合は、次のようにffillメソッドを使います。
df.ffill(inplace=True)
df
▶︎
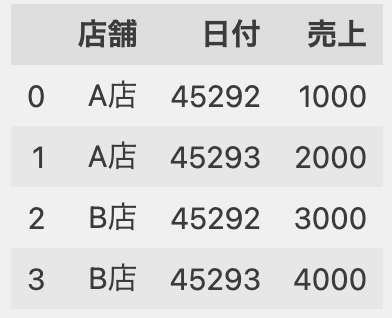
このNaNを上のセルと同じ値で補完する場合は、次のようにffillメソッドを使います。
df.ffill(inplace=True)
df
▶︎
 左右に結合されたセルの場合は、一番左のフィールドだけ値が反映するため、次の記述で補完します。
df.ffill(inplace=True, axis=1)
なお、以前は「fillna(method='ffill')」と記述していましたが、fillnaメソッドのmethod引数は廃止される予定で、現在はffillメソッドとbfillメソッドが推奨されています。
【選択肢2】
日付を含むExcelファイルをread_excel関数で読み込む場合、日付が数値になることがある。
正しい説明です。
Excelの書式設定によっては、選択肢1のDataFrameのように日付がシリアル値になることがあります。Excelの日付は1900/01/01が基準となっており、内部的にはそこから何日経過したか計算して日付を表現しているからです。
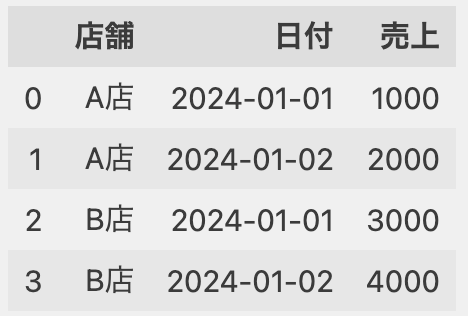
シリアル値になった場合は、次の記述でdatetime型に変換します。
df['日付'] = pd.to_timedelta(df['日付'] - 2, unit='D') + pd.to_datetime('1900/1/1')
df
▶︎
左右に結合されたセルの場合は、一番左のフィールドだけ値が反映するため、次の記述で補完します。
df.ffill(inplace=True, axis=1)
なお、以前は「fillna(method='ffill')」と記述していましたが、fillnaメソッドのmethod引数は廃止される予定で、現在はffillメソッドとbfillメソッドが推奨されています。
【選択肢2】
日付を含むExcelファイルをread_excel関数で読み込む場合、日付が数値になることがある。
正しい説明です。
Excelの書式設定によっては、選択肢1のDataFrameのように日付がシリアル値になることがあります。Excelの日付は1900/01/01が基準となっており、内部的にはそこから何日経過したか計算して日付を表現しているからです。
シリアル値になった場合は、次の記述でdatetime型に変換します。
df['日付'] = pd.to_timedelta(df['日付'] - 2, unit='D') + pd.to_datetime('1900/1/1')
df
▶︎
 シリアル値から-2をしている理由は以下です。
【1】Excelが1900/1/1を0始まりではなく1始まりとしているから。
【2】Excelは本来は存在しない1900/2/29(うるう年)を有効な日付としているから。
【選択肢3】
MultiIndexのDataFrameをto_excelメソッドで書き出すとエラーになる。
誤った説明です。
MultiIndexのDataFrameをto_excelメソッドで書き出すと、該当箇所のセルが結合されます。
次のように、インデックスがMultiIndexになっているDataFrameを書き出すと、AとBのセルがそれぞれ結合されます。
df = pd.DataFrame(
[[1,2],[3,4],[5,6],[7,8]],
index=[['A','A','B','B'],
['C','D','C','D']])
df
▶︎
シリアル値から-2をしている理由は以下です。
【1】Excelが1900/1/1を0始まりではなく1始まりとしているから。
【2】Excelは本来は存在しない1900/2/29(うるう年)を有効な日付としているから。
【選択肢3】
MultiIndexのDataFrameをto_excelメソッドで書き出すとエラーになる。
誤った説明です。
MultiIndexのDataFrameをto_excelメソッドで書き出すと、該当箇所のセルが結合されます。
次のように、インデックスがMultiIndexになっているDataFrameを書き出すと、AとBのセルがそれぞれ結合されます。
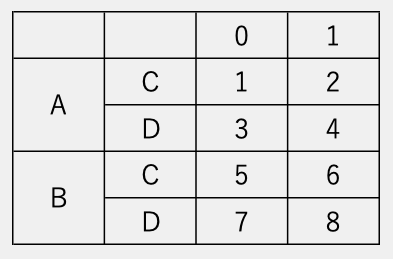
df = pd.DataFrame(
[[1,2],[3,4],[5,6],[7,8]],
index=[['A','A','B','B'],
['C','D','C','D']])
df
▶︎
 df.to_excel('sample.xlsx')
sample.xlsx
▶︎
df.to_excel('sample.xlsx')
sample.xlsx
▶︎
 【選択肢4】
二つのDataFrameを、一つのExcelファイルで二つのシートに分けて書き出す場合は、ExcelWriter関数を使う。
正しい説明です。
例えば次のDataFrameがある場合を考えます。
df1 = pd.DataFrame(
[[1,2],[3,4]])
df2= pd.DataFrame(
[[5,6],[7,8]])
次のようにwith文とpandasのExcelWriter関数を使うことで、一つのExcelファイルで二つのシートに分けて書き出すことができます。
with pd.ExcelWriter("sample.xlsx") as writer:
df1.to_excel(writer, sheet_name='sheet1')
df2.to_excel(writer, sheet_name='sheet2')
(公式書籍 p.31-36)
【選択肢4】
二つのDataFrameを、一つのExcelファイルで二つのシートに分けて書き出す場合は、ExcelWriter関数を使う。
正しい説明です。
例えば次のDataFrameがある場合を考えます。
df1 = pd.DataFrame(
[[1,2],[3,4]])
df2= pd.DataFrame(
[[5,6],[7,8]])
次のようにwith文とpandasのExcelWriter関数を使うことで、一つのExcelファイルで二つのシートに分けて書き出すことができます。
with pd.ExcelWriter("sample.xlsx") as writer:
df1.to_excel(writer, sheet_name='sheet1')
df2.to_excel(writer, sheet_name='sheet2')
(公式書籍 p.31-36)
df = pd.read_excel('sample.xlsx')
df
▶︎
このNaNを上のセルと同じ値で補完する場合は、次のようにffillメソッドを使います。
df.ffill(inplace=True)
df
▶︎
左右に結合されたセルの場合は、一番左のフィールドだけ値が反映するため、次の記述で補完します。
df.ffill(inplace=True, axis=1)
なお、以前は「fillna(method='ffill')」と記述していましたが、fillnaメソッドのmethod引数は廃止される予定で、現在はffillメソッドとbfillメソッドが推奨されています。
【選択肢2】
日付を含むExcelファイルをread_excel関数で読み込む場合、日付が数値になることがある。
正しい説明です。
Excelの書式設定によっては、選択肢1のDataFrameのように日付がシリアル値になることがあります。Excelの日付は1900/01/01が基準となっており、内部的にはそこから何日経過したか計算して日付を表現しているからです。
シリアル値になった場合は、次の記述でdatetime型に変換します。
df['日付'] = pd.to_timedelta(df['日付'] - 2, unit='D') + pd.to_datetime('1900/1/1')
df
▶︎
シリアル値から-2をしている理由は以下です。
【1】Excelが1900/1/1を0始まりではなく1始まりとしているから。
【2】Excelは本来は存在しない1900/2/29(うるう年)を有効な日付としているから。
【選択肢3】
MultiIndexのDataFrameをto_excelメソッドで書き出すとエラーになる。
誤った説明です。
MultiIndexのDataFrameをto_excelメソッドで書き出すと、該当箇所のセルが結合されます。
次のように、インデックスがMultiIndexになっているDataFrameを書き出すと、AとBのセルがそれぞれ結合されます。
df = pd.DataFrame(
[[1,2],[3,4],[5,6],[7,8]],
index=[['A','A','B','B'],
['C','D','C','D']])
df
▶︎
df.to_excel('sample.xlsx')
sample.xlsx
▶︎
【選択肢4】
二つのDataFrameを、一つのExcelファイルで二つのシートに分けて書き出す場合は、ExcelWriter関数を使う。
正しい説明です。
例えば次のDataFrameがある場合を考えます。
df1 = pd.DataFrame(
[[1,2],[3,4]])
df2= pd.DataFrame(
[[5,6],[7,8]])
次のようにwith文とpandasのExcelWriter関数を使うことで、一つのExcelファイルで二つのシートに分けて書き出すことができます。
with pd.ExcelWriter("sample.xlsx") as writer:
df1.to_excel(writer, sheet_name='sheet1')
df2.to_excel(writer, sheet_name='sheet2')
(公式書籍 p.31-36)