データ分析・中級問題チェック
問題 21 /40
pandasの属性とメソッドの使い方として、誤っているものはどれか。
選択 1
shape属性で行数と列数を確認できる。
選択 2
type属性で各カラムのデータ型を確認できる。
選択 3
applyメソッドで各データに関数を適用できる。
選択 4
set_indexメソッドで特定のカラムのデータをインデックスに指定できる。
解説
選択肢2が正解です。
【選択肢1】
shape属性で行数と列数を確認できる。
正しい説明です。
DataFrameに対して「df.shape」とすると、例えば「(3, 4)」のように行数と列数が返ります。
Seriesに対して「ser.shape」とすると、例えば「(3,)」のように要素数が返ります。
shape属性はメソッドではないため、「shape()」のように丸カッコは付けません。
なお、NumPyも同じ名前のshape属性を使って配列の形状を確認できます。
【選択肢2】
type属性で各カラムのデータ型を確認できる。
誤った説明です。
各カラムのデータ型を確認できるのは、type属性ではなくdtypes属性です。
次のDataFrameのdtypes属性を確認します。
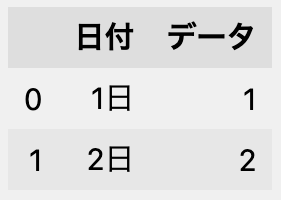 df.dtypes
▶︎
日付 object
データ int64
dtype: object
「日付」の列は文字列のためobjectとなり、「データ」の列は整数のため「int64」となります。
typeはPython標準の関数です。例えば「type(df)」とすると「pandas.core.frame.DataFrame」のようにオブジェクト自体の型が返ります。
「type」が付く属性名やメソッド名は紛らわしいので、ここでまとめておきます。
■ pandas
dtypes属性(データ型を確認)
astypeメソッド(データ型を変換)
■ NumPy
dtype属性(データ型を確認)
astypeメソッド(データ型を変換)
■ Python標準
type関数(オブジェクトの型を確認)
【選択肢3】
applyメソッドで各データに関数を適用できる。
正しい説明です。
applyメソッドはデータ1つずつに関数を適用できます。既存の関数だけでなく、自分で定義した関数も適用できます。
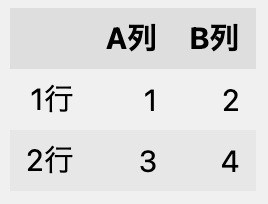
次のDataFrameがある場合を考えます。
df = pd.DataFrame(
[[1, 2], [3, 4]],
index=['1行', '2行'],
columns=['A列', 'B列'])
▶︎
df.dtypes
▶︎
日付 object
データ int64
dtype: object
「日付」の列は文字列のためobjectとなり、「データ」の列は整数のため「int64」となります。
typeはPython標準の関数です。例えば「type(df)」とすると「pandas.core.frame.DataFrame」のようにオブジェクト自体の型が返ります。
「type」が付く属性名やメソッド名は紛らわしいので、ここでまとめておきます。
■ pandas
dtypes属性(データ型を確認)
astypeメソッド(データ型を変換)
■ NumPy
dtype属性(データ型を確認)
astypeメソッド(データ型を変換)
■ Python標準
type関数(オブジェクトの型を確認)
【選択肢3】
applyメソッドで各データに関数を適用できる。
正しい説明です。
applyメソッドはデータ1つずつに関数を適用できます。既存の関数だけでなく、自分で定義した関数も適用できます。
次のDataFrameがある場合を考えます。
df = pd.DataFrame(
[[1, 2], [3, 4]],
index=['1行', '2行'],
columns=['A列', 'B列'])
▶︎
 数値が3以下か、もしくは3よりも大きいか判定する関数を作成します。
def func(x):
if x <= 3:
return 'Low'
else:
return 'High'
この関数をB列に適用して、結果をC列に記録します。
df.loc[:, 'C列'] = df.loc[:, 'B列'].apply(func)
▶︎
数値が3以下か、もしくは3よりも大きいか判定する関数を作成します。
def func(x):
if x <= 3:
return 'Low'
else:
return 'High'
この関数をB列に適用して、結果をC列に記録します。
df.loc[:, 'C列'] = df.loc[:, 'B列'].apply(func)
▶︎
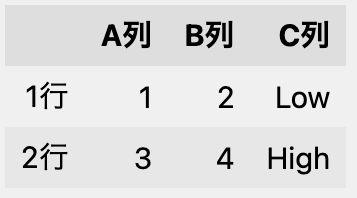 func関数の仮引数「x」にB列の値が順番に代入され、C列に結果が記録されます。
【選択肢4】
set_indexメソッドで特定のカラムのデータをインデックスに指定できる。
正しい説明です。
set_indexメソッドは、既存のカラムの値をインデックスに指定します。
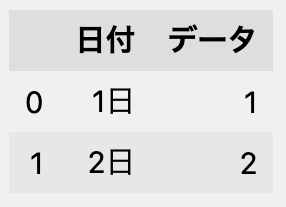
次のDataFrameがある場合を考えます。
df = pd.DataFrame(
[['1日', 1], ['2日', 2]],
columns=['日付', 'データ'])
▶︎
func関数の仮引数「x」にB列の値が順番に代入され、C列に結果が記録されます。
【選択肢4】
set_indexメソッドで特定のカラムのデータをインデックスに指定できる。
正しい説明です。
set_indexメソッドは、既存のカラムの値をインデックスに指定します。
次のDataFrameがある場合を考えます。
df = pd.DataFrame(
[['1日', 1], ['2日', 2]],
columns=['日付', 'データ'])
▶︎
 この「日付」の列をインデックスに指定します。
df.set_index(['日付'])
▶︎
この「日付」の列をインデックスに指定します。
df.set_index(['日付'])
▶︎
 なお、set_indexメソッドに引数「drop=False」を付けると、指定したカラムが移動ではなくコピーになります。また、set_indexメソッドは新たなDataFrameを返します。元のDataFrameを直接変更する場合は「inplace=True」の引数を付けます。
(公式書籍 p.152-155、158)
なお、set_indexメソッドに引数「drop=False」を付けると、指定したカラムが移動ではなくコピーになります。また、set_indexメソッドは新たなDataFrameを返します。元のDataFrameを直接変更する場合は「inplace=True」の引数を付けます。
(公式書籍 p.152-155、158)
df.dtypes
▶︎
日付 object
データ int64
dtype: object
「日付」の列は文字列のためobjectとなり、「データ」の列は整数のため「int64」となります。
typeはPython標準の関数です。例えば「type(df)」とすると「pandas.core.frame.DataFrame」のようにオブジェクト自体の型が返ります。
「type」が付く属性名やメソッド名は紛らわしいので、ここでまとめておきます。
■ pandas
dtypes属性(データ型を確認)
astypeメソッド(データ型を変換)
■ NumPy
dtype属性(データ型を確認)
astypeメソッド(データ型を変換)
■ Python標準
type関数(オブジェクトの型を確認)
【選択肢3】
applyメソッドで各データに関数を適用できる。
正しい説明です。
applyメソッドはデータ1つずつに関数を適用できます。既存の関数だけでなく、自分で定義した関数も適用できます。
次のDataFrameがある場合を考えます。
df = pd.DataFrame(
[[1, 2], [3, 4]],
index=['1行', '2行'],
columns=['A列', 'B列'])
▶︎
数値が3以下か、もしくは3よりも大きいか判定する関数を作成します。
def func(x):
if x <= 3:
return 'Low'
else:
return 'High'
この関数をB列に適用して、結果をC列に記録します。
df.loc[:, 'C列'] = df.loc[:, 'B列'].apply(func)
▶︎
func関数の仮引数「x」にB列の値が順番に代入され、C列に結果が記録されます。
【選択肢4】
set_indexメソッドで特定のカラムのデータをインデックスに指定できる。
正しい説明です。
set_indexメソッドは、既存のカラムの値をインデックスに指定します。
次のDataFrameがある場合を考えます。
df = pd.DataFrame(
[['1日', 1], ['2日', 2]],
columns=['日付', 'データ'])
▶︎
この「日付」の列をインデックスに指定します。
df.set_index(['日付'])
▶︎
なお、set_indexメソッドに引数「drop=False」を付けると、指定したカラムが移動ではなくコピーになります。また、set_indexメソッドは新たなDataFrameを返します。元のDataFrameを直接変更する場合は「inplace=True」の引数を付けます。
(公式書籍 p.152-155、158)