データ分析・中級問題チェック
問題 40 /40
scikit-learnのk-meansのクラスタリングについて、誤った説明はどれか。
選択 1
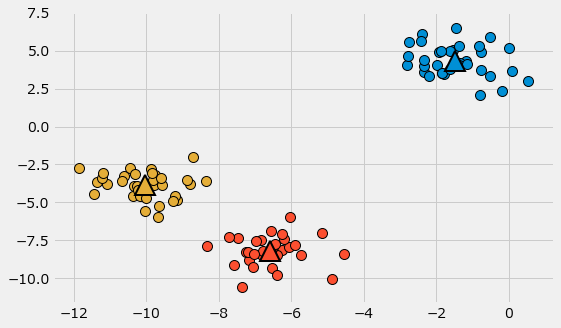
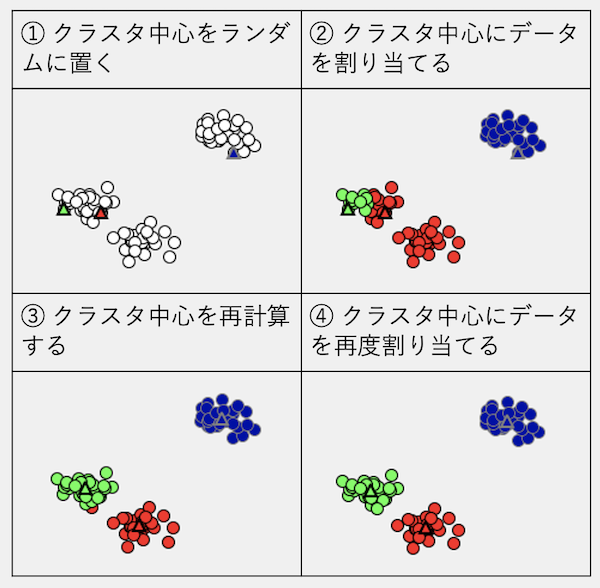
k-meansは、クラスタ中心をランダムに置いてデータを割り当て、クラスタ中心を再計算してデータを割り当て直す処理を繰り返す。
選択 2
問題文の図は、データが3つのクラスタに分割されたことを表している。
選択 3
Kmeansクラスをインスタンス化する際に、引数「n_clusters」で分割するクラスタ数を指定する。
選択 4
k-meansは線形だけではなく非線形な境界でもクラスタリングできる。
解説
選択肢4が正解です。
k-meansは次の流れでデータをクラスタリングします。
 クラスタ数は「kmeans = KMeans(n_clusters=3)」のように、KMeansクラスをインスタンス化する際に、引数「n_clusters」で指定します。
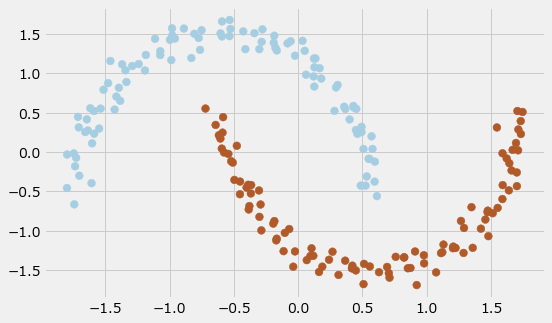
k-meansは問題文の図のように、直線(線形)で分割できるデータしか扱えません。次の図のように曲線(非線形)で分割する必要があるデータは、DBSCANなどの他の教師なしアルゴリズムを使用します。
クラスタ数は「kmeans = KMeans(n_clusters=3)」のように、KMeansクラスをインスタンス化する際に、引数「n_clusters」で指定します。
k-meansは問題文の図のように、直線(線形)で分割できるデータしか扱えません。次の図のように曲線(非線形)で分割する必要があるデータは、DBSCANなどの他の教師なしアルゴリズムを使用します。
 (公式書籍 p.264-268)
(公式書籍 p.264-268)