データ分析・上級問題チェック
問題 33 /40
scikit-learnのカテゴリ変数エンコーディングとOne-hotエンコーディングに関する説明で、誤っているものはどれか。
選択 1
カテゴリ変数エンコーディングは、カテゴリを数値に変換する。
選択 2
カテゴリ変数エンコーディングで、カテゴリを数値に変換して学習モデルを作ると、数値の大小に意味が付いてしまうことがある。
選択 3
One-hotエンコーディングは、値の分だけ列を増やし、各行の該当する値の列に1、それ以外の列に0が入力される。
選択 4
scikit-learnのOneHotEncoderクラスで変換すると scipy.sparse形式の疎行列が返るため、同じデータのndarrayよりメモリの使用量が増える。
解説
選択肢4が正解です。
【カテゴリ変数エンコーディング】
scikit-learnで学習モデルを作る場合、データを数値で渡す必要があるため、文字列だった場合は数値に変換します。
例えばある列に「北海道」「東京」「沖縄」というデータがあった場合、scikit-learnのLabelEncoderクラスでカテゴリ変数エンコーディングすると、「0」「1」「2」の数値に変わります。
これで学習できるようになりますが、数値に大小があるため、「北海道 < 東京 < 沖縄」という意味だとアルゴリズムに解釈される可能性があります。そのため、通常はカテゴリ変数エンコーディングではなく、One-hotエンコーディングを利用します。
【One-hotエンコーディング】
値の分だけ列を増やし、各行の該当する値の列に1、それ以外の列に0が入力されます。
先の「北海道」「東京」「沖縄」の例の場合、次のように変換されます。
df = pd.DataFrame(
['北海道', '東京', '沖縄'],
columns=['地名'])
▶︎
 pd.get_dummies(df)
▶︎
pd.get_dummies(df)
▶︎
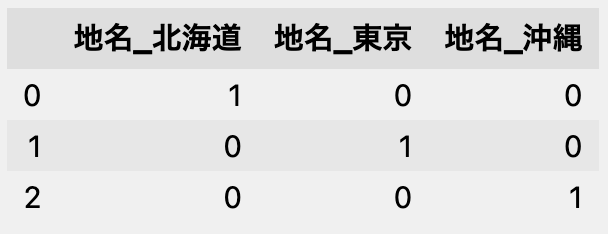 値の分だけ列が増え、各行の該当する値の列に1、それ以外の列に0が入力されます。
pandasのget_dummies関数はDataFrameが返りますが、scikit-learnのOneHotEncoderクラスはscipy.sparse形式の疎行列が返ります。
DataFrameのほうが扱いやすいですが、カテゴリが多いと0のデータが大量になるため、メモリの使用量が増えます。scipy.sparse形式の疎行列は1の位置だけ記憶して利用するため、メモリの使用量を抑えることができます。
scikit-learnのRandomForestClassifierなど、主なアルゴリズムはscipy.sparse形式の疎行列をデータとして渡すことができます。
(公式書籍 p.217-221)
値の分だけ列が増え、各行の該当する値の列に1、それ以外の列に0が入力されます。
pandasのget_dummies関数はDataFrameが返りますが、scikit-learnのOneHotEncoderクラスはscipy.sparse形式の疎行列が返ります。
DataFrameのほうが扱いやすいですが、カテゴリが多いと0のデータが大量になるため、メモリの使用量が増えます。scipy.sparse形式の疎行列は1の位置だけ記憶して利用するため、メモリの使用量を抑えることができます。
scikit-learnのRandomForestClassifierなど、主なアルゴリズムはscipy.sparse形式の疎行列をデータとして渡すことができます。
(公式書籍 p.217-221)
pd.get_dummies(df)
▶︎
値の分だけ列が増え、各行の該当する値の列に1、それ以外の列に0が入力されます。
pandasのget_dummies関数はDataFrameが返りますが、scikit-learnのOneHotEncoderクラスはscipy.sparse形式の疎行列が返ります。
DataFrameのほうが扱いやすいですが、カテゴリが多いと0のデータが大量になるため、メモリの使用量が増えます。scipy.sparse形式の疎行列は1の位置だけ記憶して利用するため、メモリの使用量を抑えることができます。
scikit-learnのRandomForestClassifierなど、主なアルゴリズムはscipy.sparse形式の疎行列をデータとして渡すことができます。
(公式書籍 p.217-221)