データ分析・上級問題チェック
問題 36 /40
scikit-learnで、次のような0〜9の手書き数字を識別する場合、正しい説明はどれか。

選択 1
数値を予測するので、分類ではなく回帰である。
選択 2
画像はデータ量が多いため、ディープラーニングでしか識別できない。
選択 3
決定木で画像の識別はできない。
選択 4
正解データがない教師なし学習でもクラスタリングできる。
解説
選択肢4が正解です。
【選択肢1】
数値を予測するので回帰である。
誤った説明です。
「0、1、2、3、4、5、6、7、8、9」という切れ目のあるクラスに分けるため、分類問題です。
【選択肢2】
画像はデータ量が多いため、ディープラーニングでしか識別できない。
誤った説明です。
問題文のデータはscikit-learnのdigitsデータで、0〜9の手書き数字が1797画像あります。1画像につき縦8ピクセル×横8ピクセルで合計64の説明変数がありますが、ディープラーニングだけでなくサポートベクタマシンなどでも分類できます。
【選択肢3】
決定木で画像の予測はできない。
誤った説明です。
画像もピクセルごとの数値データであるため、決定木やランダムフォレストで分類できます。
以下は、digitsデータをランダムフォレストで分類した結果です。
-------------------------------
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
digits = load_digits()
Xtrain, Xtest, ytrain, ytest = train_test_split(digits.data, digits.target, random_state=0)
model = RandomForestClassifier(n_estimators=100)
model.fit(Xtrain, ytrain)
ypred = model.predict(Xtest)
-------------------------------
print(metrics.classification_report(ypred, ytest))
▶︎
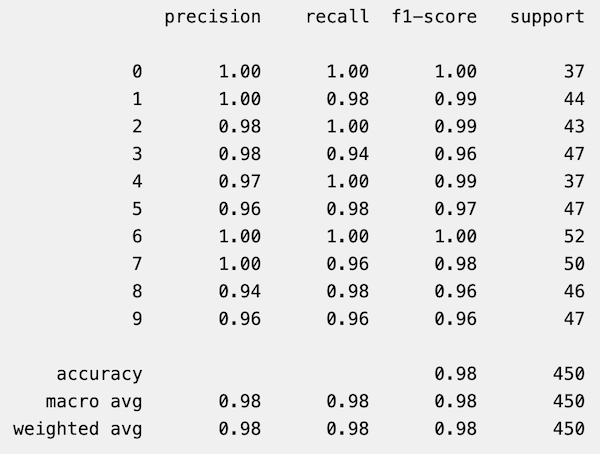 左から「適合率、再現率、F値、データ数」を表しており、どの数字も100%に近い精度が出ています。
【選択肢4】
正解データがない教師なし学習でもクラスタリングできる。
正しい説明です。
教師なし学習は正解となる目的変数がないため、「この画像が9」というように数字を特定することはできません。ただ、k-meansのような教師なし学習でも、特徴をとらえて0〜9にクラスタリングすることは可能です。
左から「適合率、再現率、F値、データ数」を表しており、どの数字も100%に近い精度が出ています。
【選択肢4】
正解データがない教師なし学習でもクラスタリングできる。
正しい説明です。
教師なし学習は正解となる目的変数がないため、「この画像が9」というように数字を特定することはできません。ただ、k-meansのような教師なし学習でも、特徴をとらえて0〜9にクラスタリングすることは可能です。