データ分析・上級問題チェック
問題 37 /40
scikit-learnの次のコードに関する説明で、誤っているものはどれか。
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
pca = PCA(n_components=2)
X_trans = pca.fit_transform(X)
選択 1
主成分分析をしている。
選択 2
「X = iris.data」は説明変数であり、目的変数の「iris.target」がないので学習できない。
選択 3
「PCA(n_components=2)」で、2次元のデータに変換することを指定している。
選択 4
「pca.fit_transform(X)」で、学習と変換を同時に行なっている。
解説
選択肢2が正解です。
主成分分析は教師なし学習のため、目的変数がなくても学習できます。
問題文の「iris.data」は、「がく片の長さ」など4つの次元(説明変数)が格納されています。
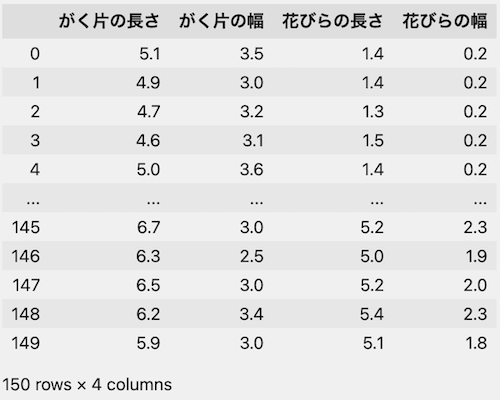 主成分分析のPCAクラスを利用すると、4つの説明変数の特徴を抽出しながら、次元を減らすことができます。
-------------------------------
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
# irisデータをロード。
iris = load_iris()
# 4つの説明変数をXに代入。
X = iris.data
# 主成分分析のPCAクラスをインスタンス化。「n_components=2」で説明変数を2つに削減することを指定。
pca = PCA(n_components=2)
# 4つの説明変数の主成分を分析し(fit)、2つの説明変数に削減(transform)。
X_trans = pca.fit_transform(X)
-------------------------------
主成分分析のPCAクラスを利用すると、4つの説明変数の特徴を抽出しながら、次元を減らすことができます。
-------------------------------
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
# irisデータをロード。
iris = load_iris()
# 4つの説明変数をXに代入。
X = iris.data
# 主成分分析のPCAクラスをインスタンス化。「n_components=2」で説明変数を2つに削減することを指定。
pca = PCA(n_components=2)
# 4つの説明変数の主成分を分析し(fit)、2つの説明変数に削減(transform)。
X_trans = pca.fit_transform(X)
-------------------------------
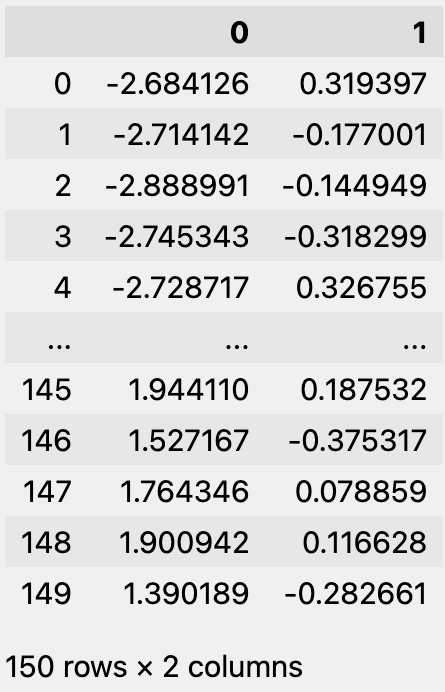 この「X_trans」を可視化すると、次の図になります。
この「X_trans」を可視化すると、次の図になります。
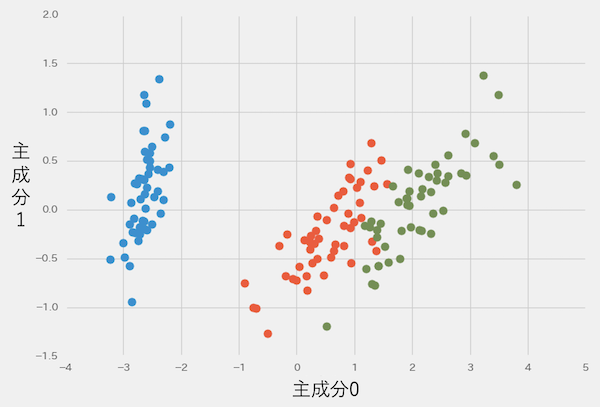 irisデータは「iris.target」に正解データがありますが、今回のように主成分分析をすることで、正解データがなくてもirisを3種類にクラスタリングできます。
このように主成分分析は、教師なし学習のクラスタリング、前処理としての次元削減、特徴量の可視化など、様々な目的で利用できます。
(公式書籍 p.246-251)
irisデータは「iris.target」に正解データがありますが、今回のように主成分分析をすることで、正解データがなくてもirisを3種類にクラスタリングできます。
このように主成分分析は、教師なし学習のクラスタリング、前処理としての次元削減、特徴量の可視化など、様々な目的で利用できます。
(公式書籍 p.246-251)
この「X_trans」を可視化すると、次の図になります。