社内文書チャットボット
2022年まで、AIの分野ではディープラーニングのモデル開発がトレンドでした。Pythonを学習し、ニューラルネットワークの理論を学び、TensorFlowなどのライブラリを使ってより良いモデルを作る。そんなプロセスが主流でしたが、ChatGPTの登場で大きく変わりました。モデル自体の開発に加えて、ChatGPTを利用するためのライブラリ開発や、ChatGPTを利用したアプリケーション開発が活発になったのです。
OpenAIのChatGPTやGoogleのGeminiは、特定の時期までのデータで学習した大規模言語モデル(Large Language Models: LLM)です。学習データにない内容については、インターネットで検索して回答されますが、外部に公開していない会社の文書などは回答できません。そこで登場したのがRAG(Retrieval-augmented Generation)の仕組みです。
RAGを利用すると、開発者やユーザーが用意したデータに対して、生成AI(LLM)を使って回答させることができます。会社に所属していると、必要な社内文書が見つからないことがよくあります。就業規則のPDFファイルがどこにあるか分からない。ファイルのリストがあっても、目的の情報がどこに書かれているか分からない。そんなとき、生成AIを利用した社内文書チャットボットが役立ちます。
目次
1. 概要
生成AIとは、プロンプト(入力)をもとにテキスト、画像、音声などの新しいコンテンツを生成するAIを指します。ここでは⑤がプロンプトで、⑥が新しいコンテンツです。
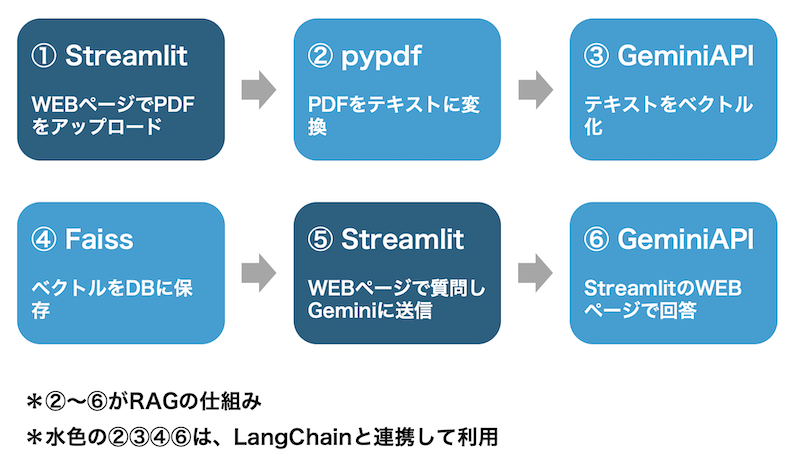
RAGはライブラリの名称ではなく、仕組みの名称です。②〜⑥がRAGの仕組みで、RAGを利用するために次のライブラリを使います。
Streamlit
フロントエンドの知識がなくてもWEBアプリを実装できるライブラリです。pandasやMatplotlibなどとも互換性があり、データサイエンスや機械学習の分野でよく使われています。
pypdf
PDFファイルを操作するためのライブラリです。テキストへの変換だけではなく、ファイルの読み込み、書き込み、編集、分割、結合などの機能もあります。
Gemini API
GoogleのGeminiをプログラムで利用するためのAPIです。通常のチャット機能だけではなく、テキストのベクトル化もできます。
Faiss
ベクトルデータを保存し、類似検索を行うライブラリです。大規模なデータも高速に検索することができます。同様のライブラリとしてChromaやVertex AI Search(Google)などもあります。
LangChain
LLMのアプリ開発を支援するライブラリです。Gemini APIなどの呼び出しを簡略化し、ドキュメントのテキスト化などをサポートします。ここでは、②③④⑥でLangChainを使います。
これらを利用して社内文書チャットボットを作ります。サンプルのPDFを用意してあるので、お試し下さい。
広告
2. 事前準備
2-1. Gemini APIキーを作成し環境変数に設定
GoogleのGeminiをプログラムで利用する場合は、APIキーが必要になります。次の流れでAPIキーを取得します。
① Google AI Studioにアクセス
②「Get API Key」をクリック
Googleのアカウントでログインして、画面右上の「Get API Key」をクリックするか、次の画面の「Get API Key」をクリックします。
③「+APIキーを作成」をクリック
画面右上の「+APIキーを作成」をクリックすると、APIキーが生成されコピーできるようになります。
④ APIキーを環境変数に設定する
APIキーをプログラムの中に記述すると、Gitなどを通して意図せずインターネット上に漏洩する可能性があります。そのため、OSの環境変数に設定します。
次の「xxx」をAPIキーに置き換えて、Macであればターミナル、WindowsであればPowerShellかコマンドプロンプトで実行します。
Mac
export GOOGLE_API_KEY='xxx'
Windows
setx GOOGLE_API_KEY 'xxx'
社内文書チャットボットで利用するGemini APIのモデルは、「gemini-2.5-flash」と「gemini-embedding-001」です。2025年9月現在、どちらも無料枠があり、テストで利用する程度であれば無料枠で収まります。Geminiはクレジットカードを登録していなければ自動で課金されることはありません。ただし、意図ぜず課金された場合、本サイトの管理者は責任を負いかねます。
また、Gemini APIの無料枠を利用すると、アップロードしたテキストがモデルの学習に利用される可能性あります。実際に社内文書を扱う場合は有料枠を利用するか、ChatGPTのAPIを利用する必要があります。現時点でChatGPTは、APIを利用してアプロードしたテキストは、モデルの学習には利用されません。ただし、意図ぜず漏洩した場合、本サイトの管理者は責任を負いかねます。
2-2. 仮想環境を作成しライブラリをインストール
Pythonの仮想環境を作成し、社内文書チャットボットで利用するライブラリをインストールします。
① Pythonの仮想環境を作成
プロジェクト用のフォルダ(ルートフォルダ)を作成し、ターミナルのcdコマンドで作成したフォルダに移動して次のコマンドを実行します。「xxx」を作成する仮想環境の名前に置き換えて実行して下さい。
python -m venv xxx
② 仮想環境をアクティベート
続けて次のコマンドを実行します。「xxx」を①で作成した仮想環境の名前に置き換えて実行して下さい。
Mac
source xxx/bin/activate
Windows PowerShell
.\xxx\scripts\activate.ps1
Windows コマンドプロンプト
xxx\scripts\activate.bat
ターミナルの左端が「(xxx)」となれば、アクティベートできています。仮想環境を抜ける場合は「deactivate」を実行して下さい。
③ ライブラリをまとめてインストール
次のrequirements.txtをダウンロードして、プロジェクトのルートフォルダに保存します。保存する場所は仮想環境のフォルダ「xxx」の中ではなく、「xxx」と同じ階層です。通常、仮想環境のフォルダの中にファイルは保存しません。
streamlit==1.33.0 pypdf==5.9.0 faiss-cpu==1.7.4 langchain==0.1.16 google-generativeai==0.5.2 langchain-google-genai==1.0.3 langchain_text_splitters==0.0.1 langchain-community==0.0.34 langchain-core==0.1.46
この段階でフォルダの構成は次のようになっているはずです。
my_project/ ← プロジェクトのルートフォルダ │ ├─ xxx/ ← 仮想環境のフォルダ └─ requirements.txt
ターミナルのカレントディレクトリはプロジェクトのルートフォルダになっているはずですが、別のフォルダになっている場合は、cdコマンドでルートフォルダに移動して下さい。
続けて次のコマンドを実行すると、ライブラリをまとめてインストールできます。インストールが終わるまで少し時間がかかります。
pip install -r requirements.txt
動作確認はPythonのバージョン3.10.7で行いました。プロジェクトによってPythonのバージョンを使い分ける場合は、バージョン管理ツールのpyenvを利用して下さい。
通常はMacでもWindowsでも動作します。ライブラリのインストールでエラーになる場合は、該当ライブラリの最新バージョンをインストールして試して下さい。
仮想環境とrequirements.txtの関連問題
広告
3. コード全体
import streamlit as st
import tempfile
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
st.title('社内文書チャットボット')
st.write('\n')
pdf_file = st.file_uploader(
label='PDFファイルをアップロードして下さい',
type='pdf')
def get_text():
if pdf_file:
pdf_text = ''
with st.spinner('PDFをロードしています...'):
with tempfile.NamedTemporaryFile(delete=False) as tmp_file:
tmp_file.write(pdf_file.read())
tmp_path = tmp_file.name
loader = PyPDFLoader(tmp_path)
documents = loader.load()
for doc in documents:
pdf_text += doc.page_content
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500)
return text_splitter.split_text(pdf_text)
else:
return None
def build_db():
pdf_text = get_text()
if pdf_text:
with st.spinner('ベクトル化しています...'):
if 'vectorstore' in st.session_state:
st.session_state.vectorstore.add_texts(pdf_text)
else:
st.session_state.vectorstore = FAISS.from_texts(
pdf_text,
GoogleGenerativeAIEmbeddings(model='models/gemini-embedding-001'))
def qa_chain():
llm = ChatGoogleGenerativeAI(
temperature=0,
model='gemini-2.5-flash')
prompt = ChatPromptTemplate.from_template('''
以下の前提知識を用いて、ユーザーからの質問に答えてください。
===
前提知識
{context}
===
ユーザーからの質問
{question}
''')
retriever = st.session_state.vectorstore.as_retriever(
search_type='similarity')
chain = (
{'context': retriever,
'question': RunnablePassthrough()}
| prompt
| llm
| StrOutputParser())
return chain
def ask_pdf():
chain = qa_chain()
if query := st.text_input('PDFへの質問を書いて下さい', key='input'):
st.write('\n')
st.markdown('##### 答え')
st.write_stream(chain.stream(query))
def main():
build_db()
if 'vectorstore' not in st.session_state:
st.warning('最初にPDFファイルをアップロードして下さい')
else:
ask_pdf()
if __name__ == '__main__':
main()
コピーしました
プログラムのルートフォルダに「main.py」の名前でファイルを作成し、このコードをコピーして保存して下さい。
この段階でフォルダの構成は次のようになっているはずです。
my_project/ ← プロジェクトのルートフォルダ │ ├─ xxx/ ← 仮想環境のフォルダ ├─ requirements.txt └─ main.py
ターミナルのカレントディレクトリはプロジェクトのルートフォルダになっているはずですが、別のフォルダになっている場合は 、cdコマンドでmain.pyを保存したフォルダに移動して下さい。
続けて次のコマンドを実行すると、WEBブラウザで社内文書チャットボットが起動します。初回の起動は少し時間がかかります。
streamlit run main.py
テスト用に2つのPDFファイルを用意しました。
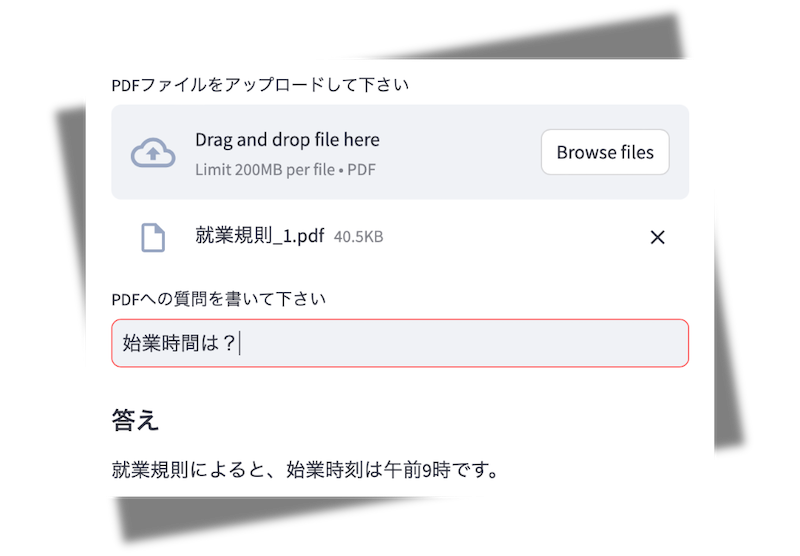
所定労働時間 1. 労働時間は、始業時刻を午前9時、終業時刻を午後6時とし、休憩時間は正午から午後1時までの1時間とする。 2. 1週間の所定労働時間は40時間とし、1日あたりの労働時間は8時間とする。
時間外労働及び残業手当 1. 所定労働時間を超える労働は、通常賃金の25%以上の割増率にて残業手当を支払う。 2. 残業代の算出方法は「1時間あたりの賃金(月給 ÷ 1か月の平均所定労働時間) × 割増率 × 残業時間」とする。
就業規則_1をアップロードして「始業時間は?」と質問すると、「午前9時」と回答します。就業規則_1をアップロードした時点では、「残業代の算出方法は?」と質問すると回答できません。続けて就業規則_2をアップロードすると、残業代の算出方法も回答します。
広告
4. コード説明
4-1. ライブラリをインポート
■ Streamlit import streamlit as st ■ tempfile, pypdf(LangChain), LangChain import tempfile from langchain_community.document_loaders import PyPDFLoader from langchain_text_splitters import RecursiveCharacterTextSplitter ■ GeminiAPI(LangChain) from langchain_google_genai import GoogleGenerativeAIEmbeddings ■ Faiss(LangChain) from langchain_community.vectorstores import FAISS ■ GeminiAPI(LangChain) from langchain_google_genai import ChatGoogleGenerativeAI from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnablePassthrough from langchain_core.output_parsers import StrOutputParser
各ライブラリは次の処理で使用しています。
Streamlit
WEBページでPDFをアップロードし、質問と回答を表示。
pypdf、tempfile
PDFをテキストに変換。
Gemini API
テキストをベクトル化し、質問に回答。
Faiss
ベクトルをデータベースに保存。
LangChain
pypdf、Gemini API、Faissを利用。
LangChainを利用することで、GeminiをChatGPTに変えたり、FaissをChromaに変えても、同様のコードで実装することができます。
4-2. WEBページのタイトル指定とPDFアップロード
1 st.title('社内文書チャットボット')
2 st.write('\n')
3
4
5 pdf_file = st.file_uploader(
6 label='PDFファイルをアップロードして下さい',
7 type='pdf')
1行目のStreamlitのtitle関数で、WEBページにタイトルを表示しています。
2行目のwrite関数で空行を挿入しています。
Streamlitを利用すると、5行目のfile_uploader関数だけでアップロードの仕組みを実装できます。
4-3. PDFをテキストに変換
1 def get_text():
2 if pdf_file:
3 pdf_text = ''
4 with st.spinner('PDFをロードしています...'):
5 with tempfile.NamedTemporaryFile(delete=False) as tmp_file:
6 tmp_file.write(pdf_file.read())
7 tmp_path = tmp_file.name
8
9 loader = PyPDFLoader(tmp_path)
10 documents = loader.load()
11
12 for doc in documents:
13 pdf_text += doc.page_content
14
15 text_splitter = RecursiveCharacterTextSplitter(
16 chunk_size=500)
17 return text_splitter.split_text(pdf_text)
18 else:
19 return None
PDFファイルをテキストに変換する「get_text関数」を定義しています。
2行目で「if pdf_file:」としているのは、PDFファイルをアップロードしたときだけテキストを変換させるためです。Streamlitはイベントが発生する度にプログラムを上から下まで再実行します。社内文書チャットボットの場合、PDFをアップロードしたり、質問を入力する度に再実行します。質問を入力したときはテキストの変換処理は不要なため、19行目のelse節で処理をスキップします。
4行目の「with st.spinner」は、アップロード中のメッセージを表示する処理です。
5行目の「with tempfile.NamedTemporaryFile(delete=False)」は、Python標準のtempfileモジュールの処理です。tempfileモジュールは、一時ファイルや一時ディレクトリを作成できます。PDFのテキスト変換で利用するpypdfモジュールは、引数にファイルを指定する必要があります。Streamlitのfile_uploader関数で生成した「pdf_file」は、ファイルではなくバイナリデータです。9行目のPyPDFLoader関数の引数にバイナリデータを指定するとエラーになるため、NamedTemporaryFile関数で「tmp_path」を一時ファイルとして定義し、引数に指定しています。
なお、PyPDFLoader関数はpypdfモジュール自体の関数ではなく、pypdfを利用するためのLangChainの関数です。LangChainにはPDF以外にも、CSVなどの多数のファイルに対応したDocumentLoaderがあります。例えばカスタマーサポートのチャットボットを作る場合は、FAQの質問と回答を列で分けたCSVファイルをアップロードすると、LLMが理解しやすくなります。
12行目のfor文で「pdf_text += doc.page_content」としているのは、複数のPDFファイルをアップロードした際に、変数「pdf_text」に追記するためです。これにより、就業規則_1をアップロードした後、就業規則_2をアップロードした際に、就業規則_1の内容も保持します。
15行目のRecursiveCharacterTextSplitterは、テキストを分割するためのLangChainのモジュールです。引数に「chunk_size=500」を指定して、500文字で分割する「text_splitter」オブジェクトを生成しています。実際に分割するのは17行目のsplit_textメソッドです。文章量が多い場合は、テキストを分割してベクトル化することで、LLMの検索効率が上がります。
tempfileの関連問題
広告
4-4. テキストをベクトル化してDBに保存
1 def build_db():
2 pdf_text = get_text()
3 if pdf_text:
4 with st.spinner('ベクトル化しています...'):
5 if 'vectorstore' in st.session_state:
6 st.session_state.vectorstore.add_texts(pdf_text)
7 else:
8 st.session_state.vectorstore = FAISS.from_texts(
9 pdf_text,
10 GoogleGenerativeAIEmbeddings(model='models/gemini-embedding-001'))
テキストをベクトル化し、データベースに保存する「build_db関数」を定義しています。
2行目のget_text関数は先に定義した関数で、PDFをテキストに変換しています。
5行目の「if 'vectorstore' in st.session_state:」は、ベクトルのデータベース「vectorstore」が存在する場合は追記する、という条件分岐です。続く「st.session_state.vectorstore.add_texts(pdf_text)」があることで、就業規則_1をベクトル化した後、就業規則_2をベクトル化した際に、就業規則_1の内容も保持します。
初めてPDFをアップロードしてベクトル化するときは、7行目のelse節が実行されます。文字列の「pdf_text」をGoogleGenerativeAIEmbeddingsでベクトル化し、Faissのfrom_texts関数でデータベースのオブジェクト「vectorstore」に保存します。このベクトル化の過程で、PDFのテキストがGeminiに送信されます。なお、2025年9月現在は「gemini-embedding-001」が利用できますが、将来廃止された場合は別のモデルを指定して下さい。
ベクトル化とは、文字列や単語を数値に変換することを指します。ベクトル化はGoogleGenerativeAIEmbeddingsが行い、ベクトル化された数値の類似度計算はFaissが行います。類似度の計算方法は、L2距離、内積、コサイン類似度などがあり、FaissをLangChainで利用する場合はL2距離がデフォルトです。Geminiはこの類似度を利用して、質問の回答として最も確率が高い単語や文章を選択します。
なお、就業規則_1をベクトル化すると、[0.00068279397, 0.006307674, 0.005791715, -0.07643665, 0.0063330214, ...]という3072個の数値に変換されます。実際にベクトル化された数値を確認する場合は、else節の中に次のコードを追加してPDFをアップロードすれば、ブラウザに先頭5個の数値が表示されます。
emb_model = GoogleGenerativeAIEmbeddings(model='models/gemini-embedding-001') result = emb_model.embed_documents([pdf_text]) st.write(len(result[0])) st.write(result[0][:5])
L2距離(ユークリッド距離)、内積、コサイン類似度の関連問題
4-5. WEBページで質問し回答
1 def qa_chain():
2 llm = ChatGoogleGenerativeAI(
3 temperature=0,
4 model='gemini-2.5-flash')
5
6 prompt = ChatPromptTemplate.from_template('''
7 以下の前提知識を用いて、ユーザーからの質問に答えてください。
8 ===
9 前提知識
10 {context}
11 ===
12 ユーザーからの質問
13 {question}
14 ''')
15
16 retriever = st.session_state.vectorstore.as_retriever(
17 search_type='similarity')
18
19 chain = (
20 {'context': retriever,
21 'question': RunnablePassthrough()}
22 | prompt
23 | llm
24 | StrOutputParser())
25
26 return chain
Geminiに質問して回答する「qa_chain関数」を定義しています。
2〜4行目のllmで、モデル「gemini-2.5-flash」を指定しています。「temperature」は回答の多様性を制御する引数です。通常は0〜1の範囲で指定し、0に近いほど一貫性がある回答になり、1に近いほどランダムな回答になります。なお、2025年9月現在は「gemini-2.5-flash」が利用できますが、将来廃止された場合は別のモデルを指定して下さい。
6〜14行目のpromptで、LLMに渡す質問と状況を指定しています。LLMは状況や役割を指定すると回答の精度が上がります。LLM は計算がやや苦手で、例えば「エベレストの標高が500メートル減少した場合に、世界で最も高い山は?」と聞くと、正しい回答は「K2」ですが、LLMのバージョンによっては回答を間違えます。回答を間違えるバージョンでも、「ステップバイステップで考えて」と加えると、正しい回答をします。
6行目の「ChatPromptTemplate.from_template」の引数は文字列で指定します。{context} と {question} も文字列の一部です。PDFの内容を{context} で指定し、質問の内容を {question} で指定しています。これらは、19〜21行目のchainオブジェクトで指定する辞書のキー「context」「question」と連携しています。
キー「context」の値は「retriever」で、これは16〜17行目で指定したPDFのベクトルDBです。16行目の「st.session_state.vectorstore.as_retriever」の引数「search_type」は、検索方法の指定です。「similarity」を指定した場合は、ベクトルDBを構築したときに設定した距離関数で類似度を計算します。キー「question」の値は「RunnablePassthrough」で、これは質問の内容を次の処理に渡すためのLangChainのクラスです。
22〜24行目のパイプ「|」はLangChainの記法です。前提知識と質問内容がpromptに指定され、それがllmに渡って、StrOutputParserで回答を得ます。StrOutputParserは、LLMの返答から必要な情報を抽出するためのLangChainのクラスです。
広告
4-6. プログラムのエントリーポイント
1 def ask_pdf():
2 chain = qa_chain()
3 if query := st.text_input('PDFへの質問を書いて下さい', key='input'):
4 st.write('\n')
5 st.markdown('##### 答え')
6 st.write_stream(chain.stream(query))
7
8
9 def main():
10 build_db()
11 if 'vectorstore' not in st.session_state:
12 st.warning('最初にPDFファイルをアップロードして下さい')
13 else:
14 ask_pdf()
15
16
17 if __name__ == '__main__':
18 main()
qa_chain関数を実行するための「ask_pdf関数」と、build_db関数を実行するための「main関数」を定義しています。
ターミナルで「streamlit run main.py」を実行すると、Pythonの内部変数「__name__」に「__main__」が代入され、18行目のmain関数が実行されます。
続けて、9行目のmain関数の中のbuild_db関数が実行され、ベクトルDBが存在しない場合は「最初にPDFファイルをアップロードして下さい」と表示します。ベクトルDBが存在する場合は1行目のask_pdf関数が実行され、質問が入力されたら6行目のchainオブジェクトでqa_chain関数が実行され、LLMが回答します。Streamlitのwrite_stream関数は、LLMの回答を一度に表示せず、順番に表示させる関数です。短い回答の場合は一度に表示されますが、長い回答の場合は順次表示されます。
3行目の「:=」はセイウチ演算子です。セイウチ演算子を使うと、変数の代入と条件判定を同時にできるため、コードが簡潔になります。セイウチ演算子を使わない場合は、最初に「query = st.text_input('PDFへの質問を書いて下さい', key='input')」と記述して変数「query」に値を代入し、続けて「if query:」と記述して条件判定する必要があります。なお、セイウチ演算子は通称で、正式名称は「代入式」です。「:=」がセイウチの目と牙の形に似ていることから「セイウチ演算子」と呼ばれています。
__main__の関連問題
5. 最後に
これで簡易的な社内文書チャットボットが実装できました。
Pythonを学習することで、GeminiやChatGPTの学習データに対して質問するだけではなく、独自のデータに質問して回答するアプリが作れます。
さらに工夫して、参照したPDFファイルの名前やパスを回答させることもできます。また、PDFに関する質問と一般的な質問の両方に対応するために、条件分岐を追加することもできます。いずれもGeminiやChatGPTに今回のコードを貼り付けて質問すれば、実装するためのコードが返ってきます。
参考書籍
シェア
広告
目次